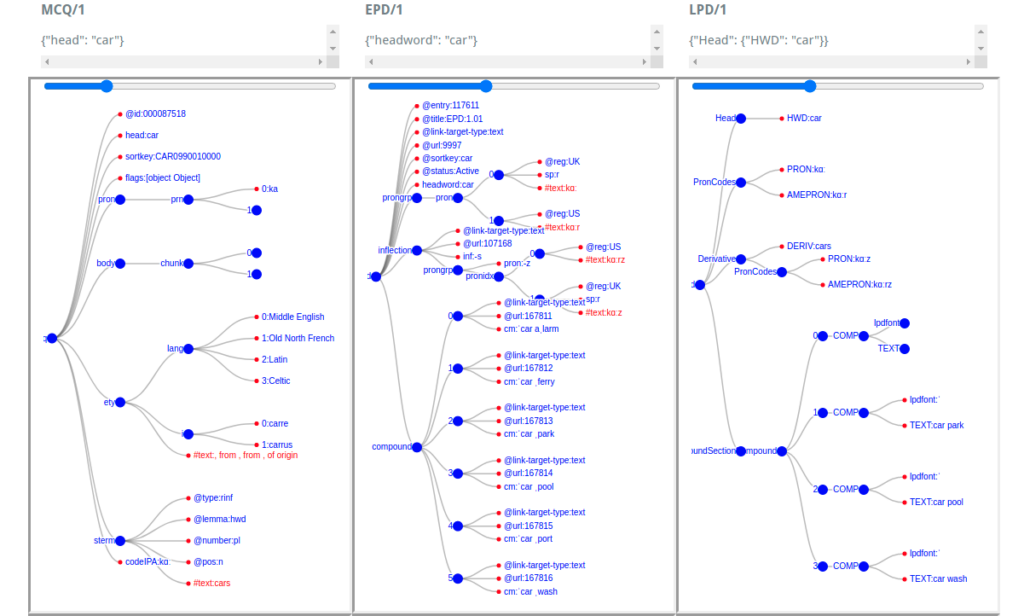
Le projet BDDictionnairique en collaboration avec l’équipe de Tours de morphophonologie du LLL a nécessité un investissement important. Une première étape nous a conduit à reprendre la solution existante (développée en Java avec Hibernate) et de construire la documentation technique associée afin d’ajouter de nouvelles fonctionnalités d’exploitation et de visualisation. Suite à une interruption faute de disponibilité, à la fondation de l’équipe ASTN une nouvelle orientation a été entreprise : nouvelle technologie et possibilité accrue par l’utilisation de technologie orientée Web. Cette nouvelle orientation nous permet d’entrevoir des ambitions plus importantes et des possibilités de traitements plus élaborés au travers de notre retour d’expérience et de la maîtrise de bibliothèques graphiques en JavaScript (D3js). De plus des approches associées à la théorie des graphes nous permettent d’ajouter des représentations facilitant l’exploitation des résultats et la validation des traitements pour l’ensemble des 69000 mots.
Représentation sous forme de graphe interactif des expressions
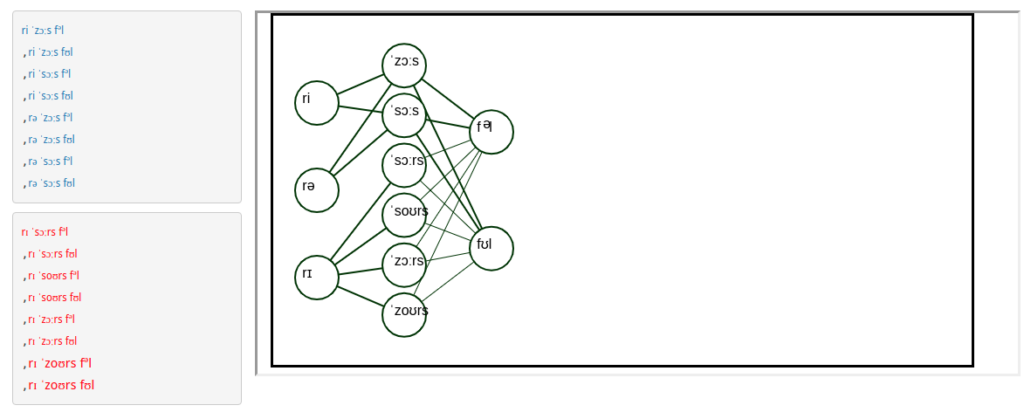
Représentation des syllabes des différentes formes de prononciations du mot sous forme d’arbre.
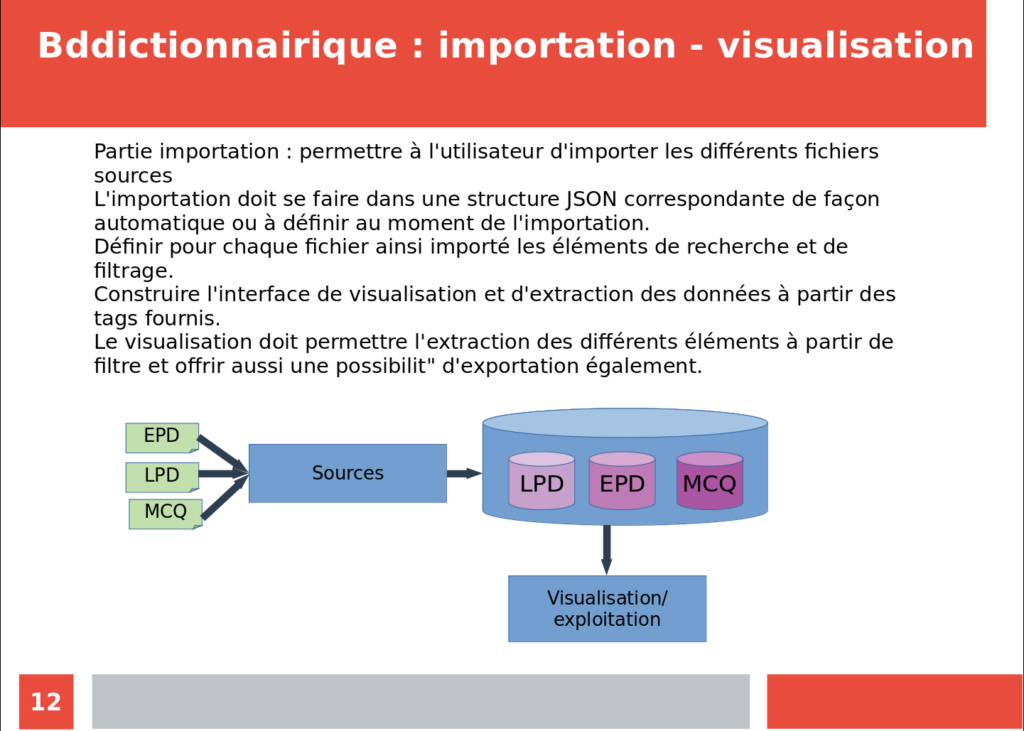
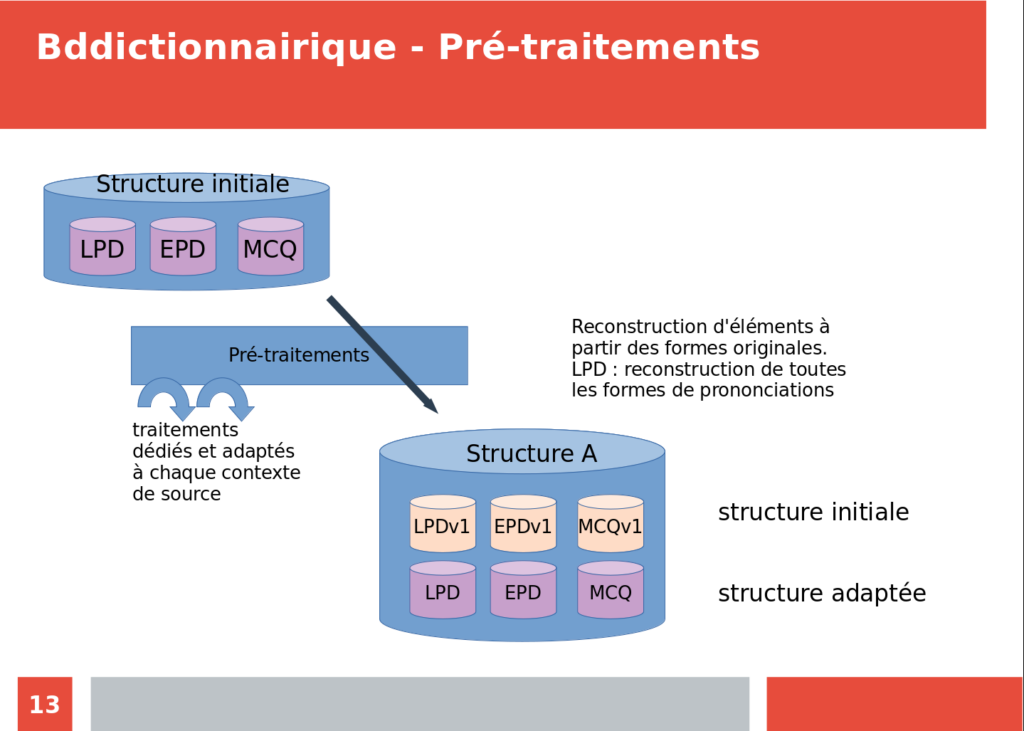
Ce projet a nécessité de reformuler et de retranscrire un ensemble de règles définies par les concepteurs de ces dictionnaires. Ces règles ensuite ont été implémentées sous plusieurs formes et langage (perl à JavaScript) pour permettre l’exécution en mode lot ou directement sur le site (en JavaScript). De plus l’outil développé s’est enrichi d’une fonctionnalité collaborative pour faciliter le travail. La méthodologie utilisée dans le cadre de ce développement nous a conduit à construire deux plateformes distinctes. La première plateforme nommée DeepBdd.org va servir à partir de données structurées ou semi-structurées à construire une représentation cohérente par le passage à travers un pipeline de traitements. Ce pipeline consiste en trois étapes que l’on peut résumer de la manière suivante :
- étape 1 : lire et extraire les données des fichiers sources
- étape 2 : regrouper et parser les données pour construire un premier ensemble cohérent
- étape 3 : fusionner/rapprocher les différentes informations issues de ces sources pour une même identification.
Ces trois premières étapes sont représentées de la manière suivante :
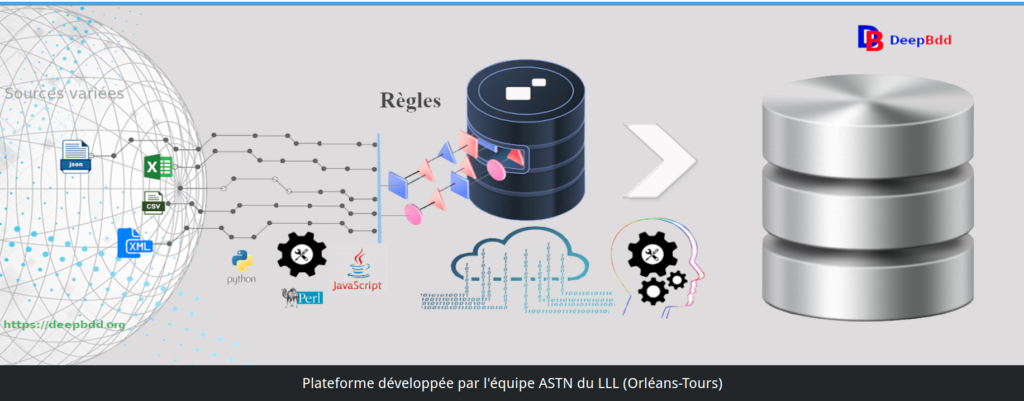
Représentation de la chaîne de traitements de la plateforme. Chaque item représente une étape dans la transformations de la données en partant de la forme d’origine vers une structure organisée permettant son exploitation. Les étapes sont détaillées et contiennent tous les éléments pour comprendre comment nous avons procédé pour agréger les données et les exposer aux utilisateurs.

Détail des différentes étapes :